Creating a Flask VAC app
As well as using frameworks such as Langserve to create HTTP versions of your GenAI applications, you can customise your own Flask VAC applications for production. Using the below sunholo boilerplate templates allows you to shortcut to GenAI features such as analytics and streaming, and hook into Multivac supported UIs such as the webapp (https://multivac.sunholo.com/), APIs, or chat bots such as Discord, Teams and GChat.
Creating your GenAI VAC
To start, create a Flask VAC application app.py - this can be autogenerated via sunholo init
# app.py
import os
from sunholo.agents import register_qna_routes, create_app
from vac_service import vac_stream, vac
app = create_app(__name__)
# Register the Q&A routes with the specific interpreter functions
# creates /vac/<vector_name> and /vac/streaming/<vector_name>
register_qna_routes(app, vac_stream, vac)
if __name__ == "__main__":
import os
app.run(host="0.0.0.0", port=int(os.environ.get("PORT", 8080)), debug=True)
This registers endpoints for your Flask app:
/vac/<vector_name>- a dynamic endpoint that you can substitute the vector_names configured in yourvacConfigfile./vac/streaming/<vector_name>- a streaming endpoint/- an 'OK' for you to check its running/openai/v1/chat/completions/<vector_name>- an OpenAI compatible API endpoint so you can use Multivac with systems that support it.
The OpenAI compatible endpoint means you can proxy requests to other model providers e.g. Gemini from applications that support OpenAI endpoints. It calls the underlying VAC just the same as via the other endpoints.
The unique logic for your app will lie within the vac_service.py file within the same folder. An example is shown below for the LlamaIndex VertexAI integration.
You need to create two functions vac_stream and vac which the framework will use to create the endpoint GenAI logic.
# vac_service.py
from sunholo.logging import setup_logging
from sunholo.utils.config import load_config_key
from sunholo.llamaindex.import_files import init_vertex, get_corpus
from vertexai.preview import rag
from vertexai.preview.generative_models import GenerativeModel, Tool
import vertexai
# streams logs to Cloud Logging for analytics and debugging features
log = setup_logging("vertex-genai")
# used as within the streaming generator function
def vac_stream(question: str, vector_name: str, chat_history=[], callback=None, **kwargs):
rag_model = create_model(vector_name)
response = rag_model.generate_content(question, stream=True)
for chunk in response:
callback.on_llm_new_token(token=chunk.text)
callback.on_llm_end(response="End stream")
# used for batched responses
def vac(question: str, vector_name, chat_history=[], **kwargs):
# Create a gemini-pro model instance
# https://ai.google.dev/api/python/google/generativeai/GenerativeModel#streaming
rag_model = create_model(vector_name)
response = rag_model.generate_content(question)
log.info(f"Got response: {response}")
return {"answer": response.text}
# this is common to both endpoints so has its own function
def create_model(vector_name):
gcp_config = load_config_key("gcp_config", vector_name=vector_name, kind="vacConfig")
if not gcp_config:
raise ValueError(f"Need config.{vector_name}.gcp_config to configure llamaindex on VertexAI")
# helper function that inits vertex using the vacConfig yaml file
init_vertex(gcp_config)
# helper function that fetches the corpus from the vacConfig yaml file
corpus = get_corpus(gcp_config)
log.info(f"Got corpus: {corpus}")
if not corpus:
raise ValueError("Could not find a valid corpus: {corpus}")
# vertexai implementation
# see https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/rag-api
rag_retrieval_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_corpora=[corpus.name], # Currently only 1 corpus is allowed.
similarity_top_k=10, # Optional
),
)
)
# load model type from vacConfig file.
model = load_config_key("model", vector_name=vector_name, kind="vacConfig")
# Create a gemini-pro model instance
# https://ai.google.dev/api/python/google/generativeai/GenerativeModel
rag_model = GenerativeModel(
model_name=model or "gemini-1.0-pro-002", tools=[rag_retrieval_tool]
)
# return model ready for vac() and vac_stream()
return rag_model
vac_stream()
This will use the streaming functions and requires:
- to have at least the arguments:
[question: str, vector_name: str, chat_history=[], callback=None, **kwargs] **kwargsmay include functions from the clients such as userId or sessionId- to use
callback.on_llm_new_token()for each new token created by the streaming function you are using.
You can also optionally use callback.on_llm_end() for any cleanup applications, and return a dictionary after all streaming is done with the answer key. This will be streamed with the ###JSON_START###{"answer": "my genai output"}###JSON_END### delimiters so the end clients can process it properly.
vac()
This is a non-streaming variant, and needs to return a dictionary with at least the answer key e.g. {"answer": "my genai output"}
Attach images
Most GenAI models like a storage location for input, not the actual image. If you want to upload an image with your request, use form data pointing to your file: it will be pre-processed before sending to the model by uploading it to the upload bucket (if available)
export FLASK_URL=https://your-deployed-url.run.app/
curl $FLASK_URL/vac/personal_llama \
-F "file=@application/webapp/public/eduvac.png" \
-F "user_input=Can you describe this image?"
/openai/v1/chat/completions
If you leave the <vector_name> blank, then the proxy will attempt to look in the config for the "model" name
e.g. if calling /openai/v1/chat/completions/ then in the config you will need a VAC called "gpt-4o"
Otherwise you can use /openai/v1/chat/completions/<vector_name> to tailor the request to the VAC eg.
This is useful for using tools such as Jan.ai as a UI for Multivac:
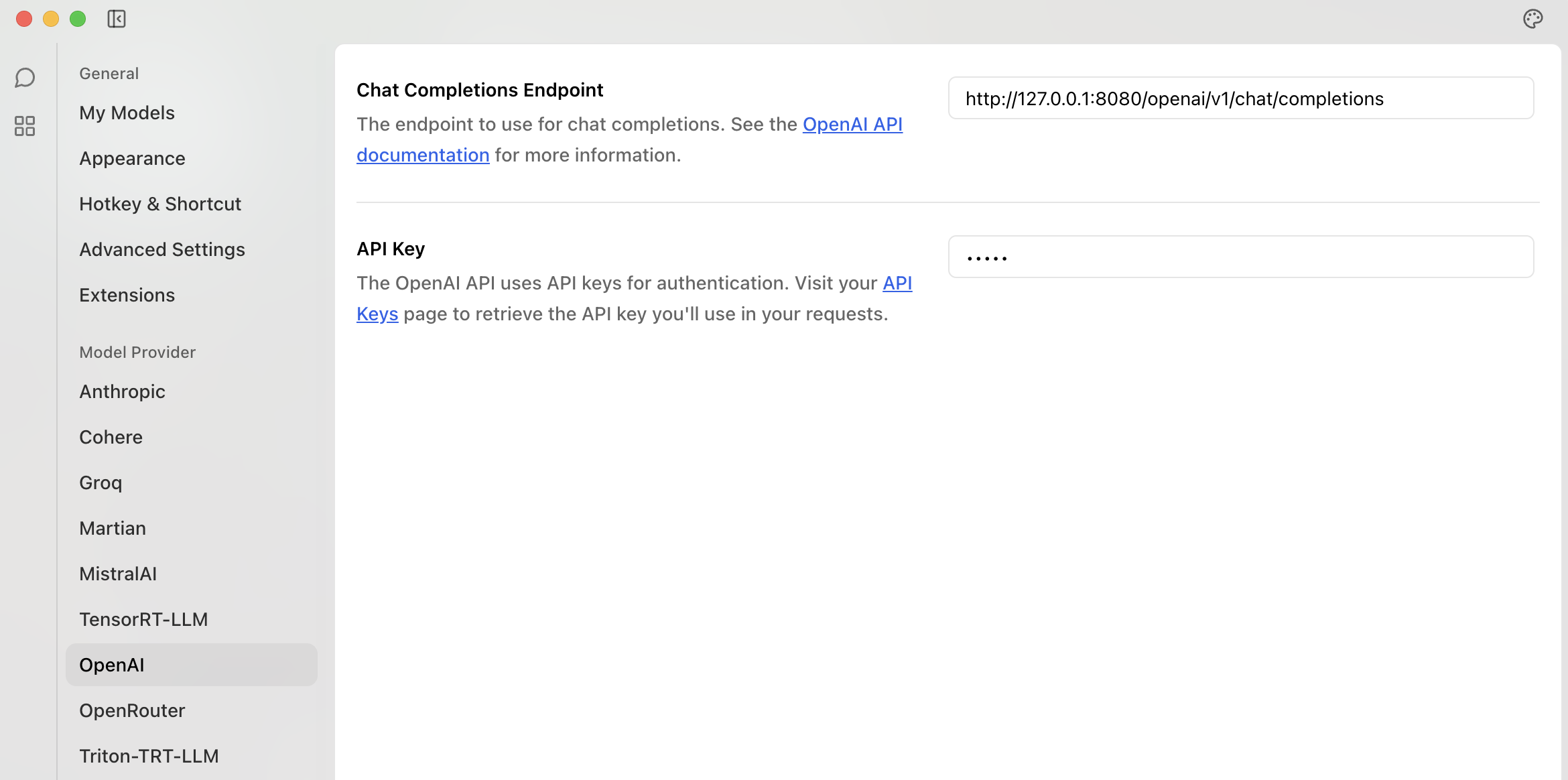
See the Jan.ai integration documentation for more information.
If authentication is being used in your requests, you will be adding a "Authorization Bearer API_KEY" header.
When using Multivac Cloud it expects usually an x-api-key for authentication, so to handle authentication the endpoints service needs to be available to check the Authentication token is the MULTIVAC_API_KEY:
ENV _ENDPOINTS_HOST=yourendpointshost.app.com
Config
An example configuration file is shown below. Read more about Configuration
kind: vacConfig
apiVersion: v1
vac:
personal_llama:
llm: vertex
model: gemini-1.5-pro-preview-0514
agent: vertex-genai # this should match the agent_config.yaml
display_name: LlamaIndex via Vertex AI
memory:
- llamaindex-native:
vectorstore: llamaindex # setup for indexing documents
gcp_config:
project_id: llamaindex_project
location: europe-west1
rag_id: 4611686018427387904 # created via rag.create for now
chunker:
chunk_size: 1000
overlap: 200
The app will use the default agent configuration within agentConfig, which includes an OpenAI compatible endpoint, a VAC unique streaming endpoint, a batch endpoint and some health check endpoints.
# agent_config.yaml
kind: agentConfig
apiVersion: v2
agents:
default:
post:
stream: "{stem}/vac/streaming/{vector_name}"
invoke: "{stem}/vac/{vector_name}"
openai: "{stem}/openai/v1/chat/completions"
openai-vac: "{stem}/openai/v1/chat/completions/{vector_name}"
get:
home: "{stem}/"
health: "{stem}/health"
response:
invoke:
'200':
description: Successful invocation response
schema:
type: object
properties:
answer:
type: string
source_documents:
type: array
items:
type: object
properties:
page_content:
type: string
metadata:
type: string
stream:
'200':
description: Successful stream response
schema:
type: string
openai:
'200':
description: Successful OpenAI response
schema:
type: object
properties:
id:
type: string
object:
type: string
created:
type: string
model:
type: string
system_fingerprint:
type: string
choices:
type: array
items:
type: object
properties:
index:
type: integer
delta:
type: object
properties:
content:
type: string
logprobs:
type: string
nullable: true
finish_reason:
type: string
nullable: true
usage:
type: object
properties:
prompt_tokens:
type: integer
completion_tokens:
type: integer
total_tokens:
type: integer
openai-vac:
'200':
description: Successful OpenAI VAC response
schema:
type: object
properties:
id:
type: string
object:
type: string
created:
type: string
model:
type: string
system_fingerprint:
type: string
choices:
type: array
items:
type: object
properties:
index:
type: integer
message:
type: object
properties:
role:
type: string
content:
type: string
logprobs:
type: string
nullable: true
finish_reason:
type: string
nullable: true
usage:
type: object
properties:
prompt_tokens:
type: integer
completion_tokens:
type: integer
total_tokens:
type: integer
home:
'200':
description: OK
schema:
type: string
health:
'200':
description: A healthy response
schema:
type: object
properties:
status:
type: string
'500':
description: Unhealthy response
schema:
type: string
However, if you add other endpoints or wish to specify it directly, use the VAC name and add those endpoints to the agent_config.yaml file
# agent_config.yaml
kind: agentConfig
apiVersion: v1
agents:
vertex-genai:
post:
stream: "{stem}/vac/streaming/{vector_name}"
invoke: "{stem}/vac/{vector_name}"
get:
home: "{stem}"
response:
stream:
'200':
description: An OK stream
schema:
type: string
...
Deploy
TBD
Into Multivac Cloud
Locally
Your own Cloud
Testing
Assuming you have a vacConfig setup with the personal_llama VAC name, you can then call the app with the following curl commands:
export FLASK_URL=https://your-deployed-url.run.app/
curl ${FLASK_URL}/vac/personal_llama \
-H "Content-Type: application/json" \
-d '{
"user_input": "What do you know about MLOps?"
}'
# {"answer":"MLOps stands for machine learning operations. It is a methodology for the engineering of machine learning systems that combines the machine learning element, ML, and the operations element, Ops. MLOps promotes the formalization of important parts of the machine learning system\u2019s construction, standardizing many steps along the way. Some of the key tasks that MLOps addresses include training models, processing data, deploying models, and monitoring models.","trace":"158cd3ba-fabd-4295-bdf3-6be335673ecb","trace_url":"https://langfuse-url.run.app/trace/158cd3ba-fabd-4295-bdf3-6be335673ecb"}
Private VACs
If the VAC is setup for non-public access within the VPC, then use the following gcloud command to proxy the VAC service:
# proxy the vertex-genai Cloud Run service if not public
gcloud run services proxy vertex-genai --region=europe-west1
Creating new VAC instances
If you want a new endpoint, add another entry to the vacConfig e.g. personal_llama2
An example configuration file is shown below.
kind: vacConfig
apiVersion: v1
vac:
personal_llama:
llm: vertex
model: gemini-1.5-pro-preview-0514
agent: vertex-genai
display_name: LlamaIndex via Vertex AI
memory:
- llamaindex-native:
vectorstore: llamaindex
gcp_config:
project_id: llamaindex_project
location: us-central1
rag_id: 4611686018427387904 # created via rag.create for now
chunker:
chunk_size: 1000
overlap: 200
personal_llama2:
llm: vertex
model: gemini-1.5-pro-preview-0514
agent: vertex-genai
display_name: Another LlamaIndex via Vertex AI
memory:
- llamaindex-native:
vectorstore: llamaindex
gcp_config:
project_id: llamaindex_project
location: europe-west1
rag_id: 2323123123213 # created via rag.create for now
chunker:
chunk_size: 1000
overlap: 200
...and call the same URL with your new VAC:
curl ${FLASK_URL}/vac/personal_llama2 \
-H "Content-Type: application/json" \
-d '{
"user_input": "What do you know about MLOps?"
}'