The AI Protocol Revolution: A Story of History Repeating Itself

Here at Sunholo, we've specialised in deploying GenAI applications for the past few years. Recently, when talking to new prospects we have noticed a trend: they show us their own internal chatbot, built at great expense just 18 months ago, and ask why it feels already outdated compared to ChatGPT or Gemini. Is there a better way to keep on the cutting edge but still keep your AI application bespoke? The answer takes us on a journey through web history, emerging protocols, and a future that's arriving faster than most realize.
Listen to a NotebookLM generated podcast about this blogpost:
AI Web = Web 1.0 / 2.0 ?
Remember Web 1.0? That nostalgic era of disparate hobby websites, the dot-com bubble, and the rise of search engines? One framing of that era could be that web-enabled companies were offering a new way to access their databases, transforming their data into HTML web portals. This read-only access gave birth to the information superhighway, and we felt a boom (and bust) as that data was given in exchange for traffic and ad revenue.
Web 2.0 evolution occurred when companies started to let users WRITE as well as READ to those databases. Suddenly websites could update in real-time with user generated content: blog comments, tweets, social interactions. Facebook and others then built walled gardens around that data and monetised it with personalised feeds, selling user behaviour to companies for highly targeted advertising in exchange for enhanced communications with one another.
The AI evolution could be said to be following the same pattern, only accelerated. ChatGPT started with conversations with static models, with chat history context. Then everyone got excited by vector embeddings and RAG for passing in their own data into the model's context window and prompts. Now users and 3rd parties can bring their own data, as Agentic AI reaches out for other sources. But there's a problem.
The Integration Nightmare
MIT's recent study claimed that 95% of generative AI pilots fail to achieve rapid revenue acceleration:
But that tells only part of the story. What they don't say is why.
One reason could be that self-build AI applications need to have unique user interfaces or unique data to be any better than the generic AI applications. If you don't have either of those (preferebly both) then you are going to be going head-to-head with hyperscalers with more resources than you. To be of value, your internal AI tools needed custom integration with internal data sources and custom UIs, and home-spun solutions can quickly become outdated as the rapid pace of AI abilities outpaces developer project time.
What's the answer? Standards. It is the experience from thousands of AI deployments across the world that has enabled AI commmuity feedback necessary for standard protocols to emerge.
The Protocols Emerge (MCP & A2A)
In November 2024, Anthropic released the Model Context Protocol (MCP). It addressed the emerging need for AI industry standards for what everyone was building, but in slightly different ways. MCP isn't particularly unique in its properties, much like HTTP wasn't. The value of a protocol comes only if and when it gains widespread adoption.
Anthropic was the perfect source for this initiative. They're respected by developers for their model's coding capabilities but also neutral enough, being deployed across Google Cloud, AWS, and Azure, to be trusted by everyone.
Then in April 2025, Google announced the Agent2Agent (A2A) protocol, backed by 50+ tech companies
While MCP connects AI to tools and data, A2A defines how AI agents collaborate. It's the difference between giving workers tools and teaching them to work as a team.
The A2A protocol again would only be of value if it was not a vendor lock-in to Google, so it was deliberately kept vendor-neutral, transferred to the open source Linux Foundation project and so is also endorsed by competitor AI companies such as AWS, Salesforce, ServiceNow, Microsoft and IBM. Like HTTP before it, A2A's value only emerges through universal adoption.
From HTTP to A2A: How Protocols Shape Technology Eras
HTTP/HTML
1990sWeb 1.0 - Companies offered read-only access to databases in exchange for traffic
SSL/HTTPS
1995The first protocol to enable trust in online commerce - without it, no Web 2.0
3D Secure
2001Like AP2 for humans - proving you authorized that credit card transaction
Web 2.0 APIs
2000sCompanies let users WRITE to databases, creating social platforms and targeted ads
OAuth 2.0
2012Enabled the app ecosystem - let services talk without sharing passwords
ChatGPT Launch
Nov 2022The moment AI became accessible to everyone - sparking the custom chatbot gold rush
GPT-4
Mar 2023The pace of change that makes 18-month-old chatbots feel obsolete
Google Bard/Gemini
Mar 2023Big Tech enters - now everyone needs to keep up with multiple AI providers
MCP
Nov 2024The integration nightmare ends - AI can now connect to any tool without custom code
A2A
Apr 2025AI agents can now collaborate - the difference between tools and teams
AP2
Sep 2025The agent economy arrives - AI can hire AI, pay per use, no humans required
The Next Step: AI Commerce
Google's recent Agent Payments Protocol (AP2) is an extension to A2A, developed with 60+ organisations including Mastercard and PayPal
AP2 adds what might be the most transformative element. Entirely new business models can now emerge based on the value added by each individual agent, and those negotiations on buying and selling can also be done by the AP2 enabled agents with or without human intervention.
Picture this: Your market research agent needs real-time data. It automatically purchases $0.02 worth of web scraping from a data harvester agent, then pays $0.05 to a sentiment analysis specialist for processing, $0.01 to a fact-checker agent for verification, and finally $0.03 to a visualisation agent for charts. Hundreds of micro-transactions per minute, agents bidding for work, specialised models competing on price and quality. No humans involved, just AI agents trading skills and knowledge in a digital marketplace. The agent economy isn't coming; it's being built right now.
How A2A and MCP Work Together
Here's a practical example of how these protocols interact in a real-world scenario: A company's research agent needs to analyze market data across multiple languages and data sources:
In this example:
- A2A Protocol handles agent-to-agent communication: The company's research agent discovers and coordinates with external specialist agents
- MCP Protocol connects agents to tools and data: Each agent uses MCP to access databases, APIs, and file systems
- AP2 Protocol manages micropayments: External agents charge small fees automatically without human intervention
- LLMs provide the intelligence: Agents use various models (Claude, GPT, Gemini) for their specific tasks
The beauty is that the company's research agent doesn't need to know how the translation agent works internally, or which LLM it uses. It just sends an A2A task request and receives results. Similarly, agents don't need custom integrations for each tool—MCP provides a standard interface to everything from databases to SaaS APIs.
The Living Laboratory
Google Agentspace, already deployed at companies like Wells Fargo, KPMG, and Nokia, shows what this A2A led infrastructure looks like in practice. It's one of Google Cloud's fastest-growing products ever. See a demo video below - the Agent Gallery is all enabled by A2A:
That dusty SharePoint archive from 2015? Suddenly searchable alongside this morning's Slack conversations. The rigid SAP system that took six months to integrate? Now accessible to AI agents without touching a line of code. Agentspace leverages A2A and has announced an A2A marketplace for seamless integration with its platform from all: including non-Google vendors, would-be rivals and open-source competitors.
As proof of that commitment to avoid vendor lock-in, the A2A protocol works with all major AI frameworks such as Langchain and Pydantic AI but also including Google's own ADK, demonstrating the power of unified AI access to enterprise data.
Embrace inflexible standards to be flexible in delivery
After the first two years post Chat-GPT in the AI trenches, we are seeing a pattern for the AI early adopters. A lot of companies that were cutting edge in 2023 — the ones who built chatbots plus RAG for internal document search — are now stuck. They can't keep up with the pace of AI improvements by the hyperscalers. Every time Gemini, Claude or OpenAI releases an update such as artifacts, thinking tokens or code execution, they face months of integration work to match it with less resources.
This is the bitter lesson of AI applied to AI infrastructure. As Rich Sutton writes:
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin." Over a long enough timespan, specialised solutions lose to general approaches that leverage computation.
But we're learning a corollary: rigid infrastructure becomes tomorrow's technical debt, fast. For example, the "chat-to-PDF" features of 2023 usually involved data pipelines that are now redundant in modern AI deployments since that feature is now just one AI API call away. The PDF parsing pipelines that were developed and worked in 2023 are now actually hindering performance of PDF understanding if unable to use the new vision or file multi-modal abilities of modern AIs.
The solution isn't just technical, but philosophical. Build for change, not features. Every AI component needs to be independently replaceable, like swapping batteries rather than rewiring your house. When OpenAI, Google or Claude releases a new model or feature next month (and they will), you should be able to adapt to it within hours, especially in this AI-code assisted future. If you get it right, then your application automatically improves in lock step with the AI models underneath it. The restrictions of complying with protocols give you the freedom to be flexible.
Get it wrong however, and you are stuck with old features that your staff do not use in favour of "shadow AI" being used via personal phones or bypassing VPN controls. Why that matters? Those interactions are incredibly valuable in assessing what your colleagues are actually working on, including what drives are important for your company. Passing that to a 3rd party and not having those AI conversations available for your own review gives the keys to your business improvement elsewhere, out of your control.
The Non-Human Web Emerges
Humans are becoming less likely to be direct consumers of web data. We may soon reach peak human web traffic, with the proportion of human traffic ever declining from now on in favour of AI bot traffic.
 Chart from https://www.economist.com/business/2025/07/14/ai-is-killing-the-web-can-anything-save-it
Chart from https://www.economist.com/business/2025/07/14/ai-is-killing-the-web-can-anything-save-it
Google's AI Overviews now appear in over 35% of U.S. searches, with some sites reporting traffic drops of up to 70%. According to Pew Research, just 8% of users who encountered an AI summary clicked through to a traditional link—half the rate of those who didn't
Think about your own behavior. How often do you ask ChatGPT or Google's AI for information instead of visiting websites yourself? Now multiply that by billions of users and add AI agents that never sleep, never get tired, and can visit thousands of sites per second.
Currently, there's a booming market for web scrapers—tools that help AI read websites designed for humans. But we propose that this is transitional, like mobile websites before responsive design. The same databases that generate HTML for humans are able to generate tailored AI responses via MCP and A2A directly to AI agents, without the messy parsing of HTML.
Another current alternative is /llm.txt which AI-savvy websites are using, that simply do the parsing for the AI without the need of going via a HTML parsing tool. It strips away all the messy HTML and offers text only content for hungry AI to process. We're building a parallel web for machines.
The Business Model Breaking Point
The impact on media and content businesses is existential. Cloudflare (who can see ~20% of total web traffic, 63 million requests per second) data shows that for every visitor Anthropic refers back to a website, its crawlers have already visited tens of thousands of pages. OpenAI's crawler scraped websites 1,700 times for every referral, while Google's ratio was 14-to-1
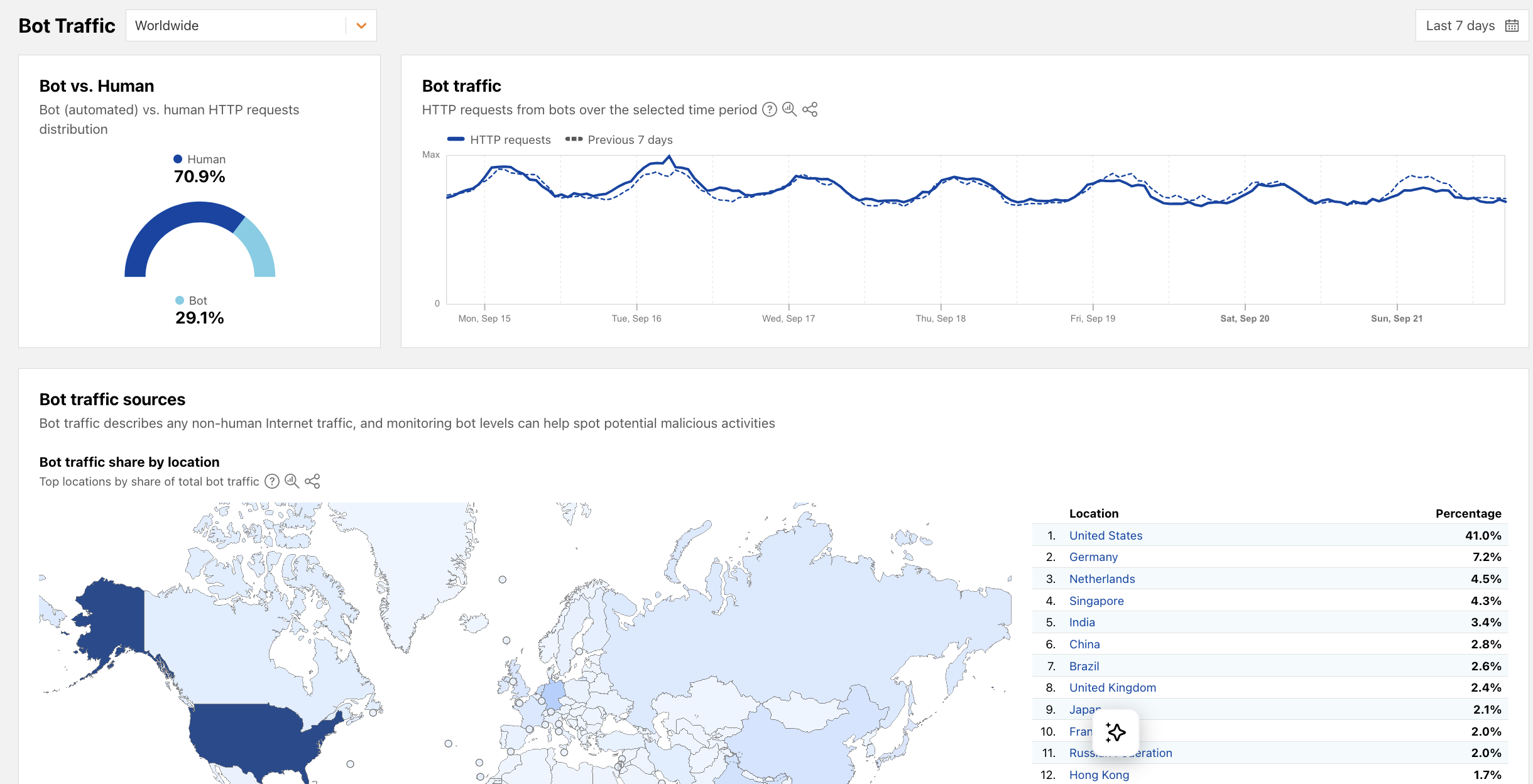
Cloudflare tracks human vs bot traffic in its radar dashboard https://radar.cloudflare.com/bots
This unsustainable imbalance led to a radical response. In July 2025, Cloudflare announced it could block AI crawlers by default and launched "Pay Per Crawl" — a solution where publishers can charge AI companies for each page crawled. It's the first serious attempt to create a new business model for the AI era, where content isn't just consumed but compensated. Here the current HTTP protocol is invoked, using an obscure HTTP access code 402 (as opposed to 404, 200 etc) indicating "Payment Required".
The Human Question
What happens to humans in this new world? Beautiful showroom websites will likely remain as spaces for inspiration and brand experience. But the messy functionality of websites: complex forms, comparison shopping, detailed research, could likely shift to AI agents working in the background.
Some companies are betting on the "everything app" approach. OpenAI and X.com seem to envision users never leaving their platforms, consuming all content through a single AI interface. It's Web 2.0's walled gardens taken to their logical extreme.
How does this impact web analytics? E-commerce conversion rates? Media websites that survived on impression-based advertising now face an extinction-level event.
The Privacy Revolution Returns
There's a twist in our story that harks back to Web 2.0's original promise: users controlling their own data.

What if individuals maintained their own A2A or MCP servers? All your purchase history, preferences, relationships, and interests in one place, under your control. You'd grant selective access to services in exchange for better experiences—verified, accurate profiles instead of the creepy tracking and guessing that defines today's web.
The protocols make this technically feasible today. The question is whether a post-GDPR population, increasingly aware of privacy violations, will demand it. Could user-controlled AI servers become the next revolution?
And this time around, the privacy stakes are higher. People were worried about Cambridge Analytica interpreting signals from user behaviour via web traffic analytics potentially influencing elections via paid ads. Thats insignficiant next to the potential harm that could be done by an AI that is super persuasive, with access to all your thoughts, dreams and desires typed into its chat box.
The Inflection Point
We're witnessing the end of AI's wild west phase. Standards are emerging. The organisations recognising this shift and who are building for tomorrow's pace of change rather than today's requirements will define the next era.
The future isn't about having the best AI. It's about having AI that can collaborate with everyone else's AI, upgrade without breaking, experiment without committing, and respect user privacy and control.
The protocols are here. The early adopters are moving. The business models are being rewritten: from impression-based advertising to pay-per-crawl, from human web traffic to agent economies. The question isn't whether to embrace these standards, but whether you'll be part of the 5% that succeed or the 95% still trying to maintain custom integrations that were obsolete before they were finished.
History doesn't repeat, but it rhymes. The web's evolution from chaos to standards to walled gardens to user control could be playing out again, just faster and with artificial minds as the primary actors. Will user privacy follow the same path, or do we have a chance to reshape the balance between user and company, to preserve human dignity? The stakes look to be higher this time around.
Where does your organisation fit in this story?
Want to discuss how to navigate this transition? Reach out at multivac@sunholo.com or visit www.sunholo.com